
Matematikken blev ikke holdt frem i lyset, som den plejer – men den var der jo alligevel: Robotten/computeren, der forstod almindelig tale; søgning i store datamængder, ekspertsystemer – altsammen noget, der har krævet masser af matematik. Men jeg vover også at skrive om noget andet, som var meget centralt, nemlig Turing test. Titlen, First Law, henviser til Isaac Asimovs regler for robotter: Asimov Online.
Første lov er: Robotter må ikke slå mennesker ihjel. (Ikke skade mennesker eller lade stå til, mens mennesker bliver skadet.)
Anden lov. Robotter skal adlyde mennesker med mindre dette overtræder første lov.
Tredje lov: En robot må beskytte sig selv, så længe dette ikke er i modstrid med de to første love.
Man kan således konkludere, at robotter brugt i krig ikke er robotter…
Ekspertsystemer
Der er mange former for ekspertsystemer. De bruges som beslutningsstøttesystemer til eksempelvis revisorer eller læger. Et dansk firma, som jeg rigtig gerne henviser til, er Hugin. Man kan hente en demoversion af Hugin, som man kan lege med, hvis man ikke har et alt for stort netværk. Hugin er grundlagt af bl.a. Steffen Lauritzen, min gamle kollega, som nu er professor i Oxford og Finn Verner Jensen, som er professor i datalogi. (Om bayesianske netværk er datalogi eller matematik, er der ikke noget fornuftigt svar på. Steffen og David Spiegelhalter publicerede i 1988 en uhyre effektiv algoritme til “opdatering” (belief propagation) i Bayesianske netværk, som er hjertet i beslutningsstøttesystemer. Man kan læse en fin introduktion til Bayesianske netværk i denne artikel i Naturens verden.
Et Bayesiansk netværk beskriver mulige årsagssammenhænge. E.g. Hvis man har lungebetændelse, er der en vis sandsynlighed for, at man hoster. Hvis man ryger, er der en vis sandsynlighed for, man hoster. Hvis man har bronkitis er der en vis sandsynlighed for, man hoster, har man influenza hoster man måske etc. Så, hvad gør en læge, når en patient fortæller, at hun hoster? Hvad er den mest sandsynlige diagnose?
Hvis nu det er influenzasæson, så er den mulighed mere oplagt.
Der er altså endnu en sammenhæng; hvis det er influenzasæson er der en vis sandsynlighed for, at patienten har influenza.
Har patienten feber, spiller det tilbage: Har man influenza har man med en vis sandsynlighed feber, har man lungebetændelse kan man også have feber. Bayes’ formel kan vende sandsynligheder om: Fra symptomerne tilbage til de mulige årsager fra feber tilbage til sygdomme, fra feber OG hoste tilbage, fra feber OG hoste OG influenzasæson tilbage. Jo mere, man ved, jo bedre diagnose.
Nedenfor er et eksempel på et Bayesiansk netværk. Dyspnoea er kortåndethed. I knuderne (boblerne) står sandsynligheden for eksempelvis at en tilfældig person har kræft.
Der er for alle pilene tilkyttet sandsynligheder: HVIS man har tuberkulose eller kræft, (samlet i TbOrCa), så er der en vis sandsynlighed for at være kortåndet. Har man ikke tuberkulose eller kræft er sandsynligheden mindre (men nok ikke 0). HVIS man har været i Asien er sandsynligheden for at have tuberkulose større, end hvis man ikke har det.
Man indtaster nu f.eks., at patienten er kortåndet og har været i Asien. Softwaren opdaterer nu sandsynlighederne i de forskellige “knuder ” (belief propagation) . I knuden om kræft står nu sandsynligheden for at have kræft forudsat, man er kortåndet OG har været i Asien. Måske indtaster jeg, at patienten ikke ryger. Igen opdateres (sandsynligheden for cancer falder så i forhold til den, der står der nu ). Opdateringen er i princippet simple regneoperationer med brug af Bayes’ formel, men der er rigtig mange af dem og Lauritzen Spiegelhalter algoritmen organiserer disse regninger rigtig smart.

Samme typer underliggende net bruges, når ekspertsystemer lærer.
Turing test
Alan Turing var ansat i Bletchley Park, briternes dekrypteringssted, hvor omkring 10000 mennesker arbejdede med brydning af tyskernes krypterede beskeder, herunder Enigma. Turings ideer er grundlag for meget moderne datalogi. Især den del, der handler om, hvad man overhovedet kan få en computer til. Turing gav en abstrakt beskrivelse af en maksine, der udfører en algoritme – en Turing maskine. Det har Hans Hüttel fortalt om tidligere på bloggen
Turing test er noget helt andet, som også skyldes Alan Turing: Hvordan kan man afgøre, om man taler (eller skriver) med en robot eller med et menneske.
Turing testen er følgende test. Et menneske C skal ved at konversere (skrive replikker til og modtage replikker fra) A og B, hvoraf en er en computer, den anden et menneske. Kan C ikke kende forskel, har computeren bestået Turingtesten.
Spørgmålet om, om man kan lave maskiner, der kan tænke – kunstig intelligens – har været emne både for filosoffer og matematikere som Turing. Om det er det, man tester, i en Turing test, er omdiskuteret. Ligesom i Numb3rs her, har man lavet programmer, chatbots, som er designet til netop at bestå Turingtesten. Og så kan de ellers ikke meget andet. (Et eksempel er ELIZA, som er meget simpelt, men ret morsomt alligevel.) Pointen er, at de svarer tilpas vagt, og dermed giver indtryk af at forstå. Lidt ligesom col readings blandt clairvoyante.
Nogle danske chatbots Knud fra Odense Kommune, Emma fra forbruger Europa og Betty fra Frederiksberg Kommune. Disse bots er kun gode til det, de skal på de sites, de hører til. Så de skal kun svare fornuftigt på et begrænset antal spørgsmål. Hvis botten fra kommunen genkender ordet “pas”, kan den linke til den rigtige side. Eller spørge, hvad man mere præcist vil.
En omvendt Turing test
Kan man omvendt få en computer til at skelne mellem andre computere og mennesker? Det gør man med Captcha. Completely Automated Public Turing Test To Tell Computers and Humans Apart. De forvredne tekster, man skal læse og taste ind, for at få lov at skrive kommentarer visse steder. De er opfundet af L. von Ahn, M. Blum, N.Hopper og J.Langford fra Carnegie Mellon.
Men det er altså ikke en Turing test. Se i øvrigt også GWAP, hvor man efter sigende kan lære computere at blive bedre til noget, mennesker normalt er bedst til. Hvis altså, man selv er bedre 🙂



![frac{a_0}{2} + sum_{n=1}^infty , [a_n cos(nx) + b_n sin(nx)]](https://upload.wikimedia.org/math/f/7/1/f712dc7dc49203f6412ed644d1426ab1.png)
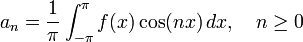
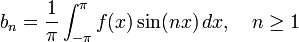

{kind=link}